Faster, fresher execution history and error analytics
- Run History and Error Analytics now use the same higher-capacity execution
data path, keeping large workspaces responsive as their history grows.
- Error Analytics combines hourly summaries with the latest runs, so recent
failures appear without waiting for the next full aggregation window.
Browse supported LLMs from the console
- Signed-in users can now explore the live LLM Router catalog without
leaving the console.
- Search and filter the available models, compare their capabilities, then
open one preselected in the playground to start testing it immediately.
Model pricing pages load reliably across pricing formats
Some Kling and MiniMax model pages could fail to load when a model used a
fixed fallback price instead of a formula. Both pricing formats are now
supported, so affected model pages and their cost estimates render normally.Prediction statuses now match everywhere
- The generated API schema now uses the same prediction status values as
production responses, including
error for failed predictions.
- Generated clients can handle terminal failures and cancellation responses
without translating between conflicting status names.
Cloned workflows start cleanly at version 1
A cloned workflow could inherit the source workflow’s active version number.
Every clone now begins at version 1, giving it a clean and predictable
version history of its own.Build workflows with up to 40 parallel branches
- A parallel step can now contain up to 40 branches, up from 10, for
wider fan-out workloads in a single workflow.
- The editor keeps large parallel steps readable with a scrollable branch
list, cleaner connections, and zoom that fits very wide flows.
See exactly what happened in a workflow run
- Workflow history now includes a builder-like flow diagram with live status
updates and clear per-step inputs, outputs, errors, duration, and cost.
- Failed runs surface their error at the relevant step, and parallel
workflows show the final merged output instead of an intermediate branch.
- You can switch between the new visual inspector and the classic detail
view at any time.
Top up without leaving your run
When a run needs more balance, you can choose a top-up amount, see an
estimate of how many similar runs it will cover, and continue to Stripe
directly from the run dialog.Find current pricing for every public model
- The pricing directory now loads current
public model prices from the live catalog.
- Search by model, filter by modality, sort by popularity, release date,
name, or price, and inspect tiered pricing without opening each model page.
Move from analytics to the exact runs behind them
- Request counts in Usage Analytics now open Run History already filtered to
the relevant model while preserving your date range and API-key filter.
- The Webhooks page gained consistent filters, clearer status indicators,
and more readable delivery details for faster investigation.
Compare models and every output side by side
- Model Comparison now offers responsive result grids, a full-screen compare
view, thumbnails, keyboard navigation, and direct downloads.
- Multi-output models display every generated result instead of showing only
the first one.
Filter your executions by error type
GET /v1/executions now accepts an error_classification query parameter,
so you can narrow a listing to just the executions that failed for a
specific reason — for example provider_rate_limit or content_moderation.- Pass a comma-separated list to match any of several types (e.g.
error_classification=provider_rate_limit,provider_unavailable); an
unrecognized value returns a 400 so typos surface immediately.
- The canonical values are
content_moderation, execution_timeout,
invalid_user_input, invalid_model_config, provider_auth,
provider_error, provider_rate_limit, provider_unavailable,
internal_error, and unknown.
Filter your files by model
- The storage page now lets you filter your
files by the model that generated them, so you can pull up everything a
given model produced in one view.
- You can also filter by source — separate the files you uploaded via the
API from the outputs each::labs auto-saved from your executions.
- These join the existing date-range, execution, and file-type filters on the
same page.
See whether a model’s error rate is normal, or just yours
- Error Analytics now lets you filter to a single model and see your
workspace’s error rate for it next to the each::labs platform-wide
average for the same model, so you can tell at a glance whether a failure
spike is something on your side or the model itself.
- The comparison is color-coded — green when you’re beating the platform
average, red when you’re worse — and the benchmark window is labeled so you
know what it’s averaged over.
- The page also gained quality-of-life upgrades alongside it: sortable
columns, CSV export, error-type tooltips, and a “Yesterday” quick range.
Set how long an uploaded file is kept
- When you upload a file you can now pass
expires_in_seconds to control how
long it’s retained. Once that window passes the file is removed
automatically, so there’s no manual cleanup to schedule.
- Leave it out and files keep the default retention, so nothing changes for
existing integrations.
- An expired file drops out of list, download, and storage totals exactly
like a manual delete, and is purged from the CDN.
Create workflows straight from the API
- You can now create a workflow programmatically with
POST /v1/workflows/create (API-key auth), so a whole pipeline can be
provisioned from code instead of only being assembled by hand in the
dashboard.
- It’s the same workflow object either way: anything you create over the API
shows up in the dashboard and runs through the existing trigger flow.
- This is the first half of full workflow management over the API — create
now, with more lifecycle operations to follow.
A new Error Analytics view shows why your executions fail
- The dashboard now has an Error Analytics page that surfaces your
workspace’s error rate and breaks failures down by type, so you can see at
a glance what’s going wrong instead of opening runs one at a time.
- Failures are also broken down per model, so you can tell which model is
driving your errors.
- It builds on the clearer, provider-side failure messages shipped earlier,
now aggregated into rates you can actually act on.
Every model now ships an OpenAPI schema
- Every model exposes an OpenAPI 3.0 schema at
GET /v1/models/{slug}/schemas/openapi, and its inputs and outputs render
as a typed reference in the model page’s API tab.
- The machine-readable schema plugs straight into code generators,
validators, and API explorers, while the same schema drives the
human-readable reference (types, required flags, defaults, enum values,
ranges).
- Coverage is automatic and always in sync: both the endpoint and the API
tab are derived from each model’s request schema, so there’s nothing to
author or maintain per model.
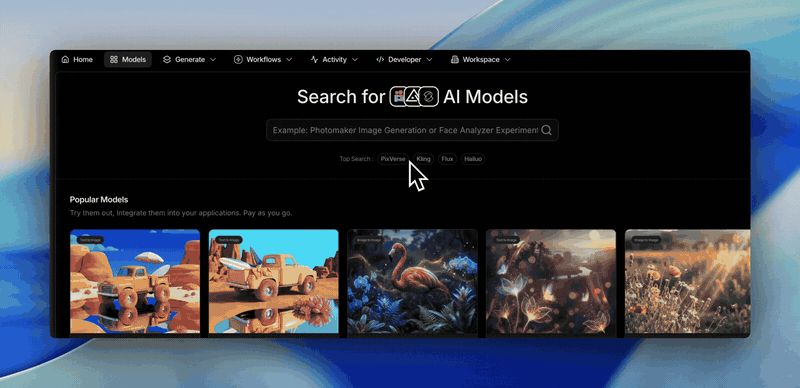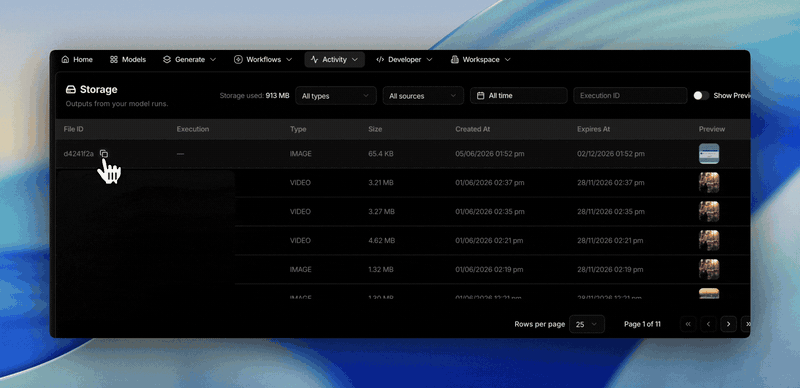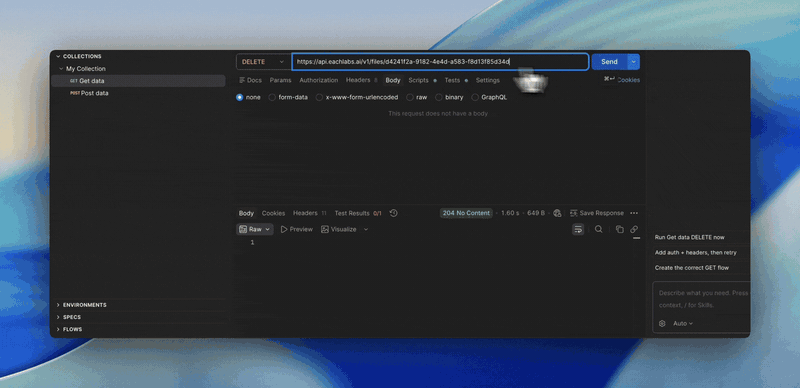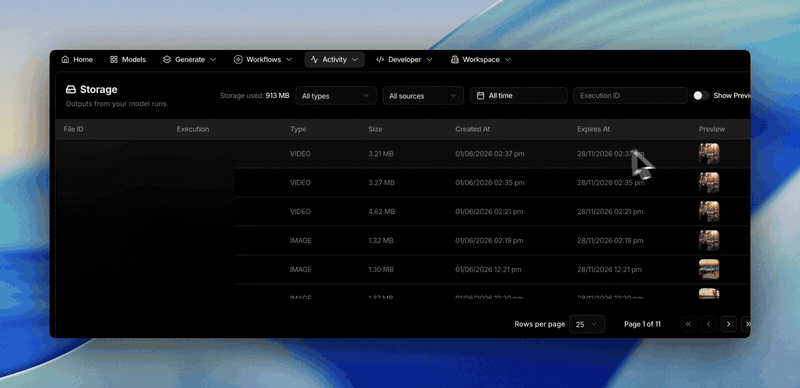
Delete an uploaded file over the API
- API customers can now delete an uploaded file with
DELETE /v1/files/:id
(API-key auth, returns 204). Files uploaded through the presign flow had
no delete path before, so once stored there was no way to remove the
object or its record. This closes that gap for storage cleanup and
data-deletion or privacy requests.
- A delete removes the S3 object and soft-deletes the record, so the file
drops out of list, download, and storage totals immediately.
- Deletes are org-scoped: callers can only delete files their own org owns.
New image models in the catalog
- MAI-Image-2.5 Edit is now available for image editing, through both the
API and the dashboard.
- Ideogram v4 is available too, with a rendering-speed selector so you
can trade quality against latency on each run.
Your API key can no longer leak from the browser
The dashboard used to keep a copy of your key in your browser. Now it never
does. Your key stays on the server and signing in uses a secure session.
Even a fully compromised browser has no key to steal. Nothing changes for
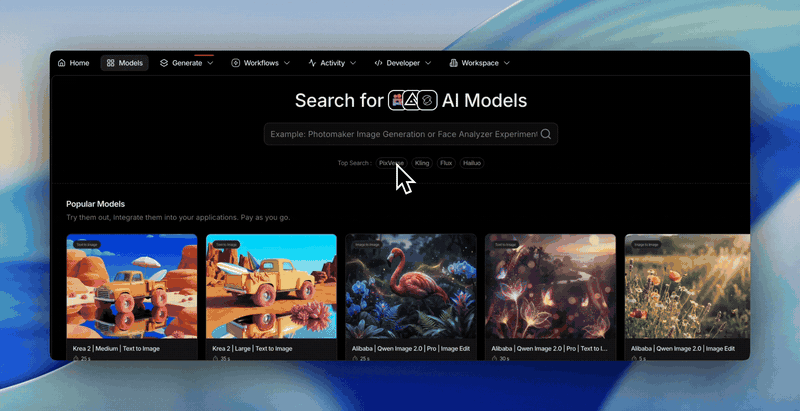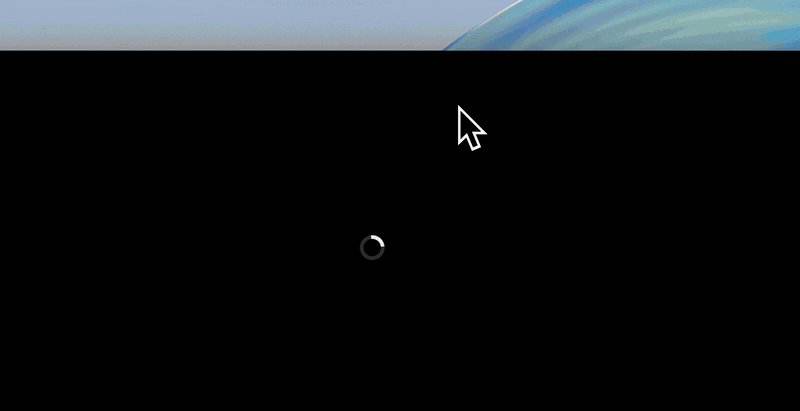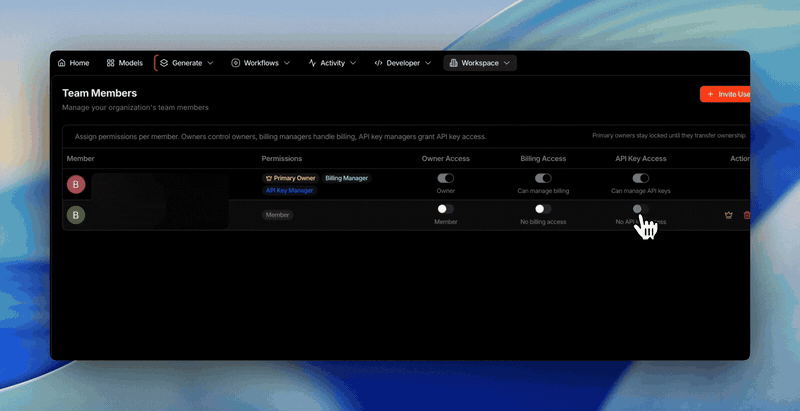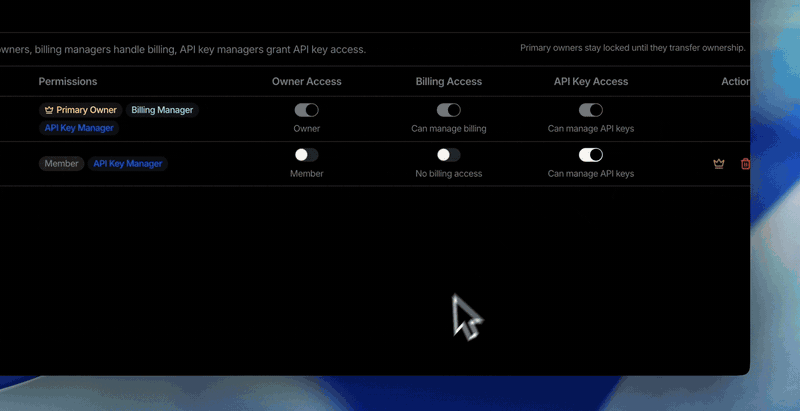
you day to day; the biggest place a key could leak is simply gone.Keys are owned by the organization, so they survive people coming and going
- Keys belong to the organization, not the person who created them. So when
a teammate leaves, their keys keep working and your integrations don’t
break.
- Any API Key Manager or the organization’s primary Owner can delete any of
the org’s keys: one place of control, no orphaned keys.
- Every key records who created it, for audit and accountability.
- A new “Can manage API keys” permission (shown as “API key access”
in the UI) controls who can create and delete keys, and only that. It
doesn’t touch billing, model access, or whether existing keys work.
- Removing that permission from someone never breaks their existing keys.
They keep working; the person just can no longer create or delete keys.
- A Manager manages all of the org’s keys; there’s no per-key granularity
today.
You hold your key, we don’t, so copy it when you create it
For security, the full key value is shown only once, at the moment you
create it, and is never stored anywhere it can be shown again. Copy it then
and keep it safe. If it’s ever lost, just create a new key and delete the
old one.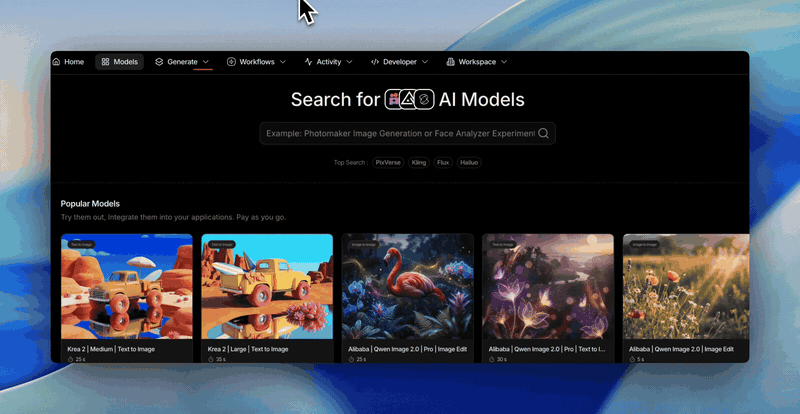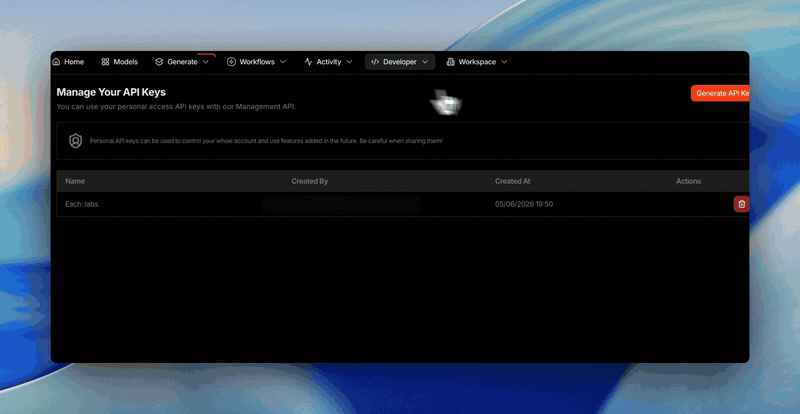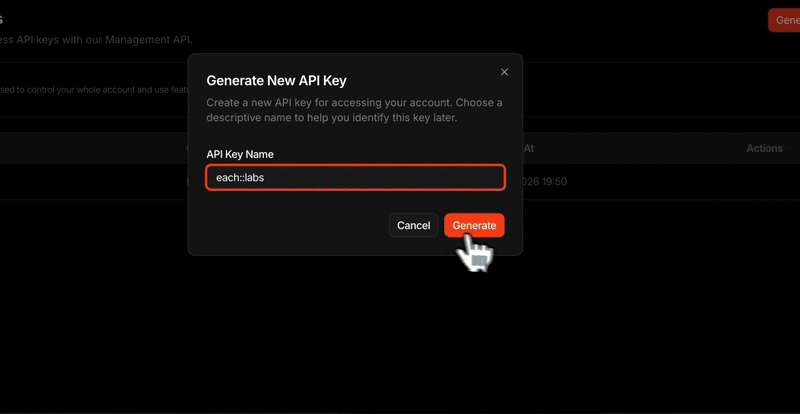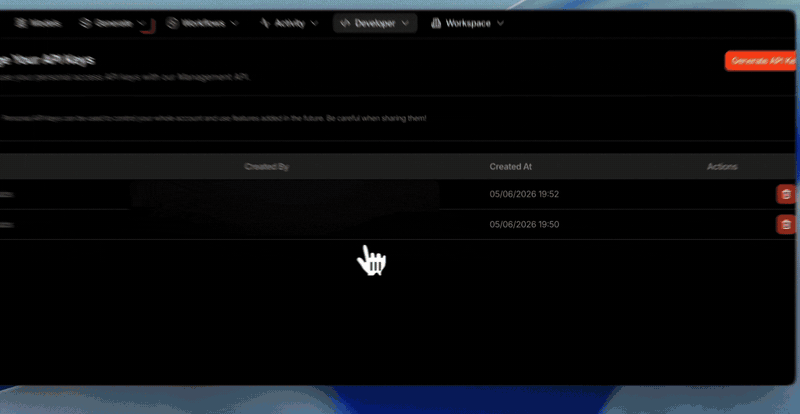
You can finally tell dashboard runs apart from API runs
- Executions, usage, and per-model request history now filter by source
(Dashboard vs API), by specific key, and by teammate, so
you can attribute every run and every dollar of spend to the right key or
person. You can even recover history from keys that were later deleted.
This came straight from customer feedback.
- The selected view is deep-linkable, so you can share a URL that lands on
exactly the breakdown you’re looking at.
- Reported usage is more accurate: internal dashboard traffic no longer
inflates your API usage totals.
Keys are recognizable at a glance: they start with smk_
The keys you create for the API now begin with smk_, so they’re easy to
spot in your code, your logs, and support tickets.New accounts start clean, no confusing unused key
Signing up no longer auto-creates a key you could neither see nor use.
Running and uploading inside the dashboard work immediately with zero
setup; you create a key only when you actually need external API access.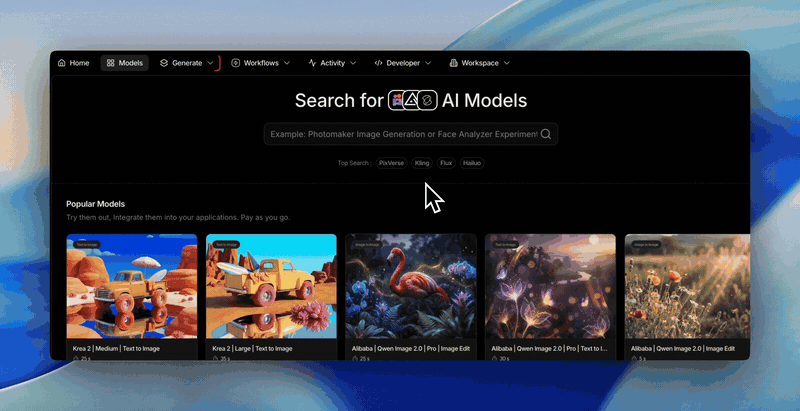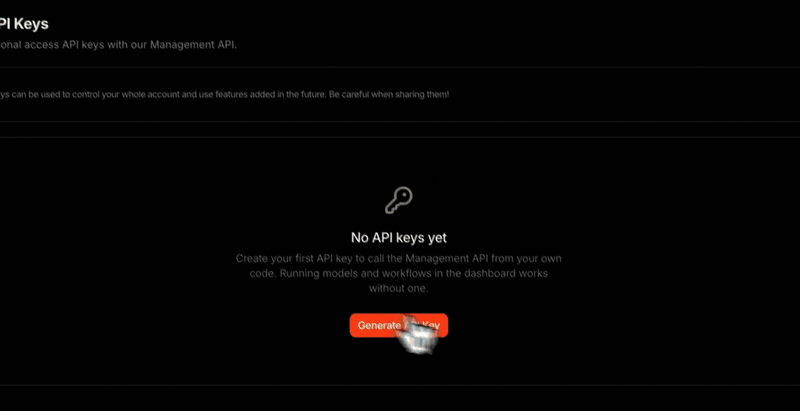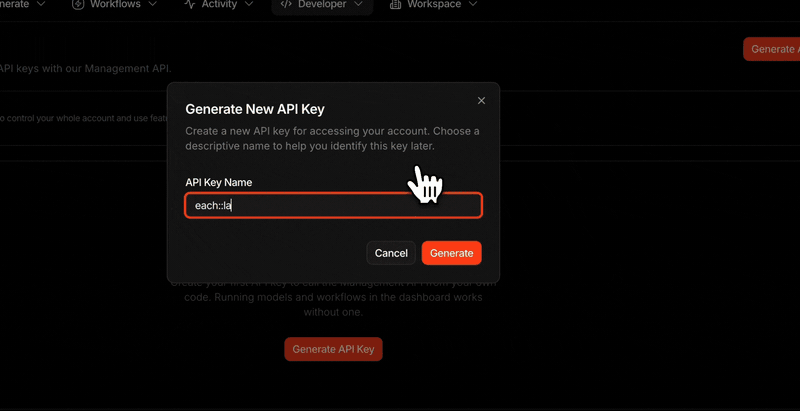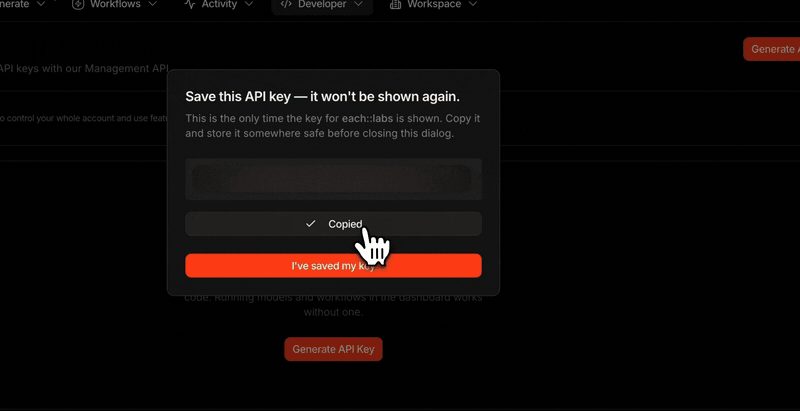
Faster model browsing
Model, provider, and family pages are rebuilt on a new data layer, with
noticeably faster loads and the newest models shown first.
A home for all your files
The storage page brings every file you’ve uploaded or generated into one
place. Browse inputs and outputs together, and filter by date range,
execution, or file type to find exactly what you need.Clearer failure messages
When an execution fails, you now get more specific error detail, including
provider-side reasons from image and video models, so you can tell what
went wrong without digging through logs.Last modified on July 13, 2026